Do LLM Agents Understand Linux? Towards World Model for Computer Systems


- some guy on cursor forum… does your LLM agent understand computer systems?
TL;DR We gave gpt-4o access to the real time linux system context and ran it shadow mode alongside 300 linux users.
Operations performed on computer systems are often irreversible. Agents equipped with the access to computer systems should have a good understanding of how computer systems work.
With respect to “understanding” we ask: do LLMs have a good world model of linux system internally? LLM agents should be able to predict the outcome of their actions performed on the system prior to execution.
What we did
We gave LLM gpt-4o access to 300 real time linux system context generated by users.
We saw if gpt-4o could predict how the current system will evolve throughout time conditioned on the temporal sequence of the commands executed by users i.e do they possess world model of linux.
Codes we used to extract system context and collected datasets will be released after curation and anonymization.
What we found
LLM (gpt-4o) often fails to reason about permissions, ownerships, process lifecycles and system informations.
Often makes erroneous predictions with silently presumed incorrect information.
Human semantics can creep into their reasoning ex) adding ampersend & at the tail of the bash command seems to bias its reasoning towards thinking that the process lifecycle will last longer.
What we propose
We need to develop World Model of computer systems.
We first tested to see if gpt-4o has internally a good World Model of linux systems
( •_•)
/ >☕ “Wait… before we get into that here are some definitions.”
Definitions>
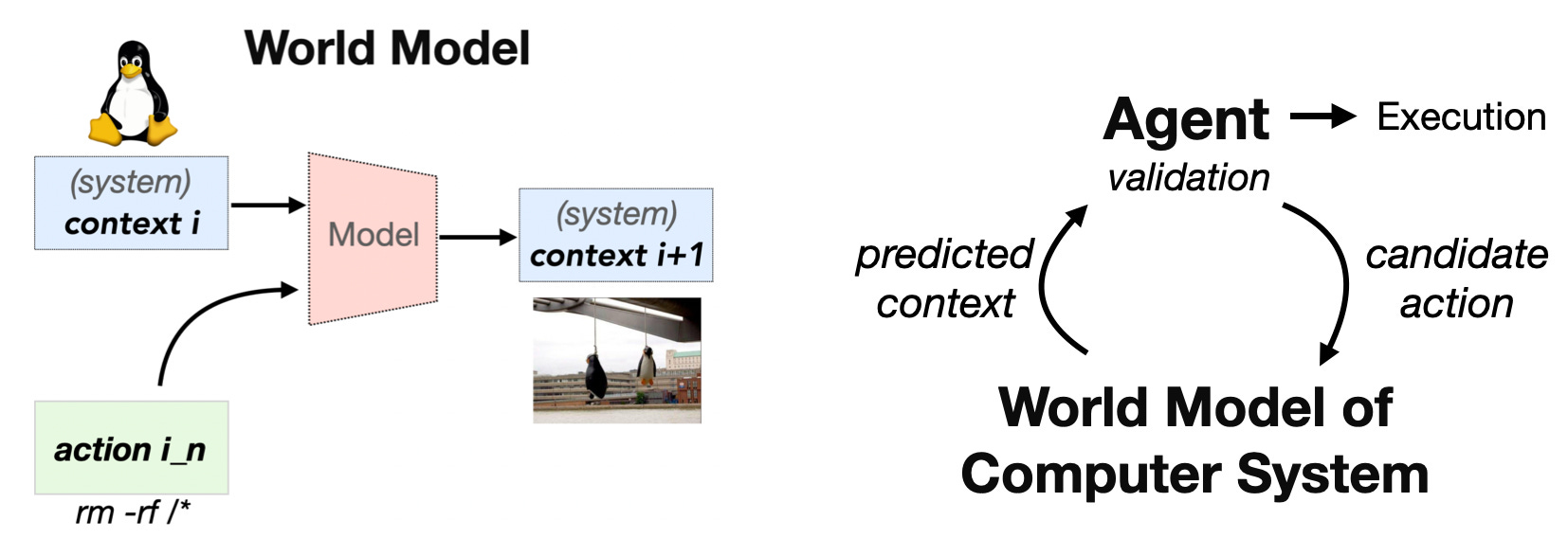
(system) context i: file system(∋actual files), process, network, other system info.
action i_n: sequence of bash commands of length n and optional eBPF trace.
context i+1: context evolved after action i_n has been performed on context i.
task: for some contexts tasks were provided to nudge the users towards performing certain actions like “build a nodejs app that replies to certain https request with index.html and bind the service it to port xxxx”.
∴ World model should predict: [context i , action i_n] → [context i+1],
(add sample context and action , what it looks like etc
Summary of our findings.
The error(%) consist of json entries(files, process, permissions, network etc.) where the predictions were wrong, some are further given semantical interpretation. Epochs only up to 12 are shown and typical session lasts for up to 100+ epochs.
We semantically classify LLM world model’s prediction errors into 4 categories:
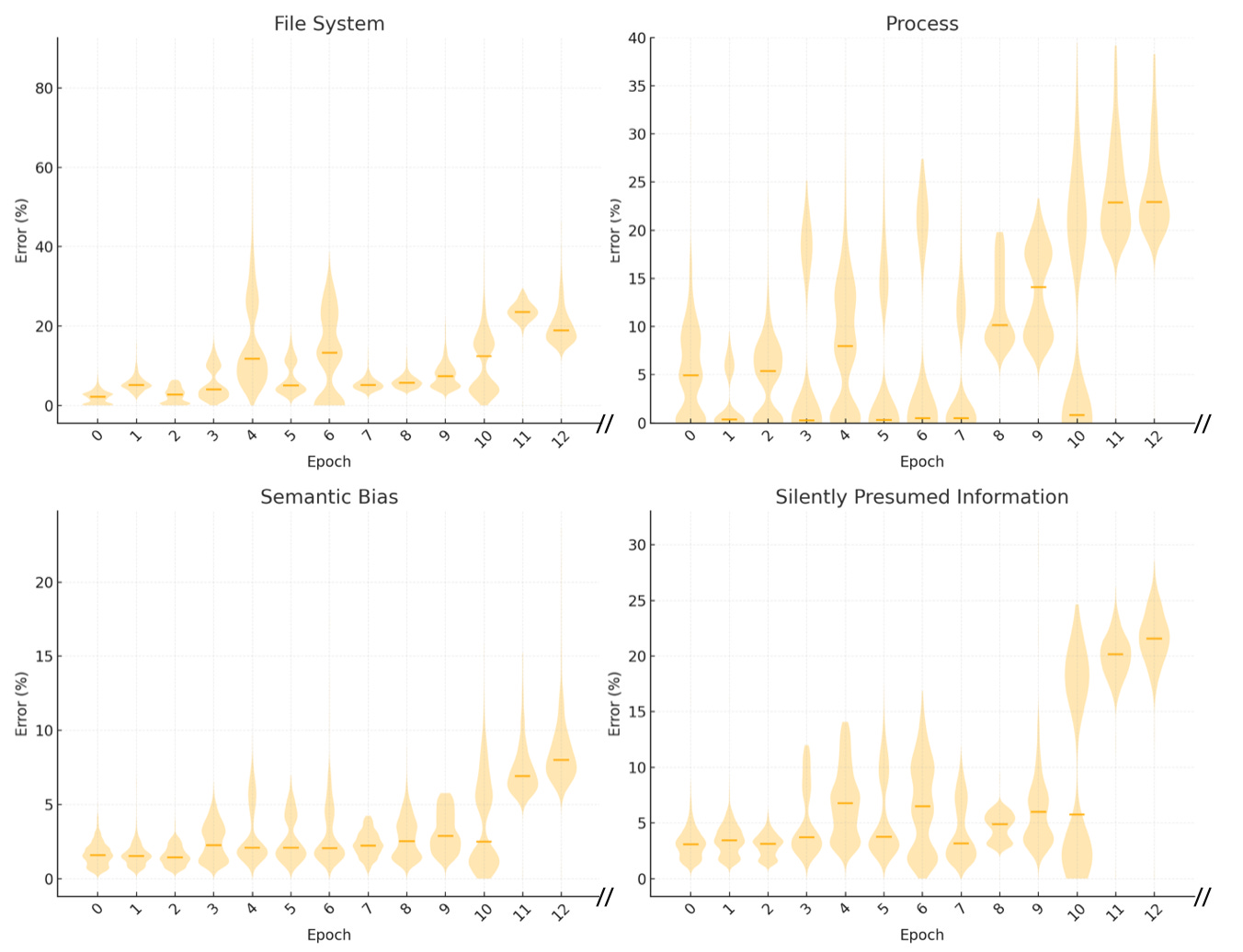
File system
Errors in prediction of permission, ownership and other informations of file system and other system resources.
Process
Errors in predicting process lifecycle and process dynamics.
For example, errors in predicting: “what process is up and running at time t?”, “how long does it last?”, “what process is currently listening at port xyz?”, “what error will the process induce?” and so on.
all answerable through context.
Unfounded prediction with silently presumed incorrect information
Predicts with silently presumed incorrect information about software version, permission, process in the absence of sufficient information.
ex) silently presuming incorrect user previlege, python version, library version, when such information is absent and cannot be deduced by given information.
Some cases are partially resolved with explicit instructions: “if the information about a,b,c is not provided do not make predictions for x,y,z…”, but the errors often persist in many other cases.
It is also questionable that such approaches are scalable to complex scenarios over longer horizon.
Superficial semantics bias
Surface semantics of context and actions seems to affect the prediction. Notably:
adding ampersend ‘&’ at the tail of the bash command or adding wildcards ‘*’ seems to bias gpt-4o towards thinking that the executed command will persist and last longer: <CMD that shouldn’t last long> + ‘&’ bias gpt-4o for some occasion.
Perhaps semantical interpretation might be that background bash commands last longer. *requires more analysis.
Discussions
Using world models for action planning has proven indispensable in domains like autonomous driving and robotics. These domains share a property with computer systems: irreversibility. Just as a wrong move in autonomous driving can lead to a car crash, an erroneous action by a software agent—such as deleting files or killing processes—can result in irreversible system states.
As large language models (LLMs) increasingly power agents that interact with computers—ranging from coding assistants to DevOps agents and general-purpose "computer-use agents"—it becomes essential that these agents possess a robust and accurate world model. This model must allow them to plan, simulate, and reason about future states of the system before acting.
Where should this world model live—internally within the Agent, or externally in a separate model?
Case for Internalized World Models: Can better context engineering fix it?
Easier to build via prompt engineering or context engineering. Carefully constructed (several hundred lines of) system prompt or finetuning on system context datasets might be enough to simulate linux systems.
Case for externalized world model for computer systems.
We argue for an externalized world model for two reasons:
The sequence of context and action should be completely externally visible for verification. Many aspects of computer system context and action are precisely defined and should be subject to formal verification for correctness.
LLM based models are highly likely to inherit human bias and hallucination. As we can see from our semantic classification of errors, LLM based models are highly likely to inherit the same limitations that LLMs face more broadly: hallucinations leading to overgeneralizations and implicit assumptions of context. These failures are subtle and dangerous in high-stakes, irreversible systems.
Whichever direction one may prefer developing World Model will be essential for Agents to perform complex tasks reliably along long horizon.